99位、パフォーマンスは2018でした。レート 1981 -> 2003(+22) でした。黄色になりました!
問題: https://atcoder.jp/contests/ahc030
GitHub: https://github.com/Kyo-s-s/AHC030
どんなことをしたのか書きます。
誤った解釈/主張をしている箇所があるかもしれません。 その場合はX(Twitter)などで教えていただければありがたいです。 XのID: @Kyo_s_s
を 油田 が(左上から) だけずらした位置にある確率 とします。 これをもとにベイズ推定を行いました。
この定め方により、任意の に対して が成り立ちます。 また、初期値は入力生成方法より一様です。
クエリ結果を とします。このとき、ベイズの定理より、
が成り立ちます。 また、 を事前確率、 を事後確率、 を尤度 と言います(あってるよね?)。
は、「事象 の元で事象 が起こる確率」 です。
事後確率 は「クエリの結果として が返ってきた下で、油田 が 位置 に存在する確率」、 尤度 は「油田 が 位置 にある下で、クエリの結果として が返ってくる確率」となります。
ベイズ推定では、クエリ毎に事後確率を求め、事前確率を更新していきます。つまり、クエリ を聞いたのち、
と更新します。
ここで、更新後も任意の に対して が成り立つことに注意すると、 は陽に求める必要はなく、一旦
と更新したのち、
とすればよいです。
以降、掘る/占い クエリ に対して を求めることを考えます。
座標 を掘って、油田の量が であることが分かったとします。 この時のクエリを と表すこととすると、求めたい値は 、つまり「油田 が位置 にある下で、 の石油埋蔵量が である確率」です。
これは、油田 が位置 にあり、
- に重ならないとき: 油田 以外を配置して、 の石油埋蔵量が になる確率
- に重なるとき: 油田 以外を配置して、 の石油埋蔵量が になる確率 ( のときは )
と等しいです。 これらの値は油田 以外についてのDPをすることで求めることができます。
そのままこの値を計算すると値が小さくなりすぎてしまい、アンダーフローが起きてしまう可能性があるかもしれません。 コンテスト中には気づかずそのまま実装してしまいました。
座標の集合 を占って、返ってきた値が であったとします。 この時のクエリを と表すこととすると、求めたい値は 、つまり「油田 が位置 にある下で、集合 を占って が返ってくる確率」です。
先に言ってしまうと、この値は厳密に求めずに適当にしてしまいました。 なので以降の文章は適当です。
を、 平均 および標準偏差 の 確率密度関数に を代入した値 とします。
各 に対して、集合 を占ってクエリ結果 が返ってくる確率 というのが、
で求められます。これを とします。 (ここで、 は集合 の石油埋蔵量の総和です。読みづらくてすみません…) ( のとき、元が負数で にまとめられるケースもあるのでこの時は から までの積分値となります) (ぼくは問題文が読めず、積分区間を から にしていました。バカ…)
今回は数値積分を用いてこの値を求めたのですが、誤差関数を使うと良いらしいです(そのほうが高速?)。
Rustでは libm::erf が使えるらしいです。
油田 を位置 に置いたとき、少なくとも の値は、 集合 の座標の中で、油田 を位置 に置いた時に重なる個数以上になります。
重なる個数を と置き、 を であるとして更新を行いました(ここが適当ポイントです、本来は他の油田の情報も考える必要があると思います)。
まず、 の島を くらいずつに分割し、占いクエリを投げます。 これにより、油田がある可能性がある/ほとんどない といったことがある程度分かります。
その後、油田量の期待値が に近い座標を掘り、確率を更新する… ということを繰り返しました。
この手法だと終盤に確率が非常に小さい箇所をたくさん掘ってしまいます。そのため、 期待値がある程度以下の座標については、掘らずにまとめて占いを行うようにしました。seed19の終盤でこの挙動をしています。
各油田について存在する位置がある程度以上特定できたとき、提出クエリを出すようにしました。
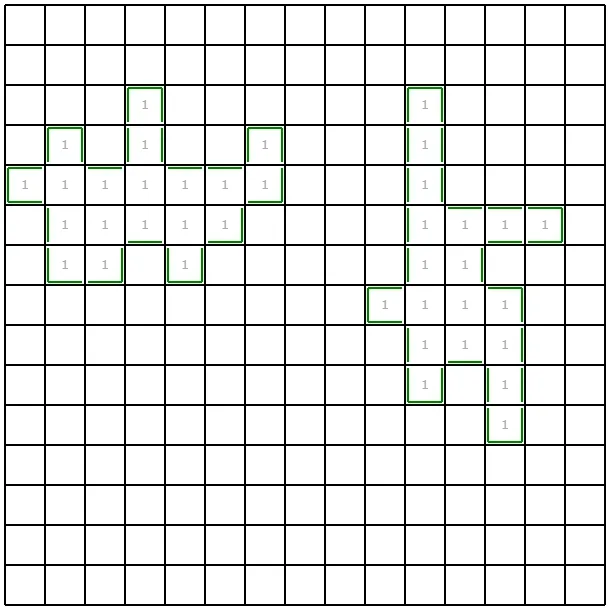 seed = 0, Score = 2800000
seed = 0, Score = 2800000
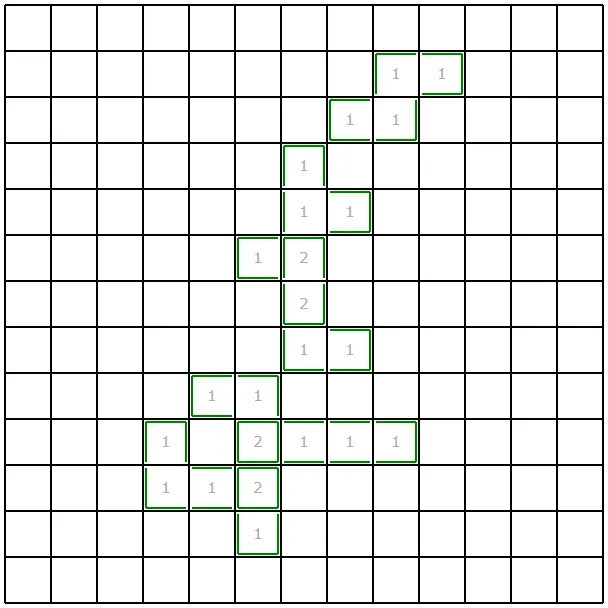 seed = 1, Score = 37982051
seed = 1, Score = 37982051
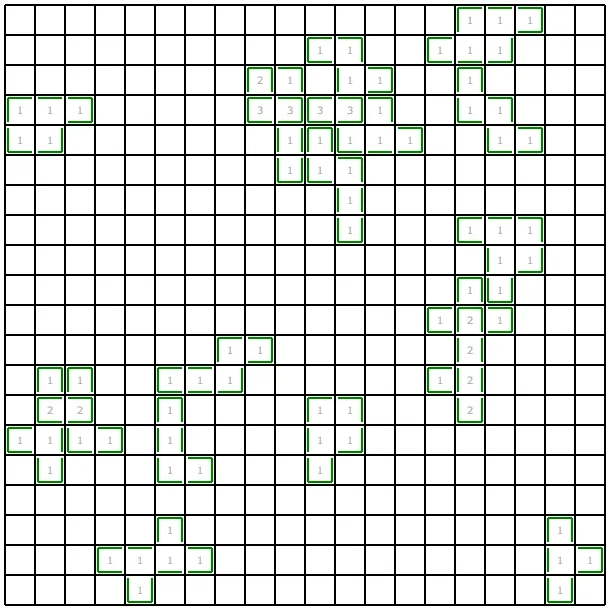 seed = 19, Score = 216280847
seed = 19, Score = 216280847
色はその座標の油田量の期待値です。 以上は緑、 は白として表示するようにしました。
占いで適当なことをしているため、基本はマス掘り戦略をしました。
(油田の個数) が小さいときには各配置に対してベイズ推定をする方針が強く惨敗していたのですが、 が大きいときにはそこそこ強かったらしいです ( ではそれぞれ 17, 31, 35位でした。 https://siman-man.github.io/ahc_statistics/030/index_m.html 参照)。
入力ケース生成方法によると が小さいケースが圧倒的に多く、負けてしまったようです。
困っています。ちゃんとやる方針を考えたのですが、重そうな気がしています。
困ります。同じ油田の形だと全く同じ遷移をしてしまい、確率が に収束しないためです。
今回は同じ形があったときには確率が高いものから採用するようにしましたが、終盤でこのことに気づいたため、だいぶ実装がごちゃごちゃになってしまいました。
コンテスト中はこれでいいじゃん!と思っていたのですが、いざ参加記を書くと本当にこれ正しいの?と疑問に思う点や、 適当すぎない?という点がたくさん出てきてしまいました。むむむ…。
とはいえこれでHeuristic黄色になりました。うれしい! この記事とは別に、Heuristic入黄記事を書くかもしれません。
もっと強くなりたい~